I'm following-up here with an implemented example.
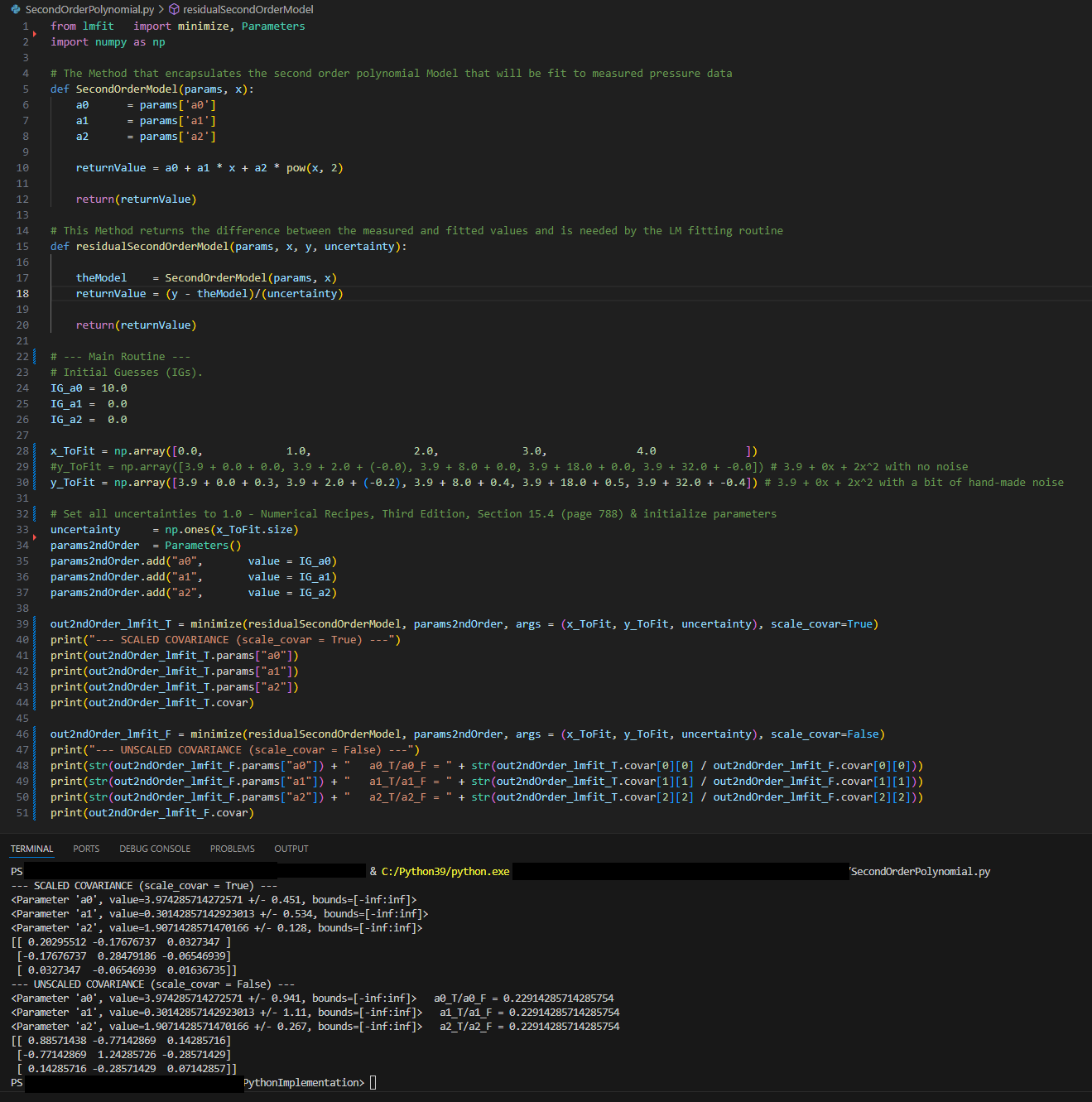
In the image below is an image of functioning example of Python. For a single dataset, a fit to a second order polynomial (y = a0 + a1*x + a2*x^2) is performed and either the scaled or unscaled covariance matrix is returned.
Attachment:
 Python_scale_covar_question.png [ 122.29 KiB | Viewed 47 times ]
Python_scale_covar_question.png [ 122.29 KiB | Viewed 47 times ]
Below is code that utilizes ALGLIB to perform a fit to the same functional form (i.e., a second order polynomial) of the same dataset. The same coefficients are found. Based on a check of the diagonal elements (see the output at the bottom of the image), the covariance matrix that is calculated by ALGLIB is the scaled covariance matrix - the diagonal values agree with the diagonal elements of the scaled covariance matrix returned by Python, not the diagonal elements of the unscaled covariance matrix returned by Python.
How can I get the
unscaled covariance matrix using ALGLIB?
Additionally, how can I get the Hessian evaluated at the minimizing point?
Code:
[TestMethod]
public void TestAlgLibSecondOrderModel()
{
var x = new double[,] { { 0 }, { 1 }, { 2 }, { 3 }, { 4 } };
//var y = new double[] { 3.9 + 0.0 + 0.0, 3.9 + 2.0 + (-0.0), 3.9 + 8.0 + 0.0, 3.9 + 18.0 + 0.0, 3.9 + 32.0 + -0.0 }; // No noise
var y = new double[] { 3.9 + 0.0 + 0.3, 3.9 + 2.0 + (-0.2), 3.9 + 8.0 + 0.4, 3.9 + 18.0 + 0.5, 3.9 + 32.0 + -0.4 };
var c = new double[] { 10.0, 0.0, 0.0 };
var epsx = 0.000001;
var maxits = 5000;
var info = 0;
alglib.lsfitstate state;
alglib.lsfitreport rep;
// Fitting without weights
alglib.lsfitcreatefg (x, y, c, false, out state);
alglib.lsfitsetcond (state, epsx, maxits);
alglib.lsfitfit (state, function_SecondOrder_func, function_SecondOrder_grad, null, null);
alglib.lsfitresults (state, out info, out c, out rep);
// Assertions
// Expected values come from Python & are also found in TestMathnetLMSolver.TestLMSolverResultsForEquation25aFitUnconstrainedCoefficients()
Assert.AreEqual(3.97, c[0], 0.01);
Assert.AreEqual(0.30, c[1], 0.01);
Assert.AreEqual(1.91, c[2], 0.01);
// Check the solver's scaled covariance results
var cov = rep.covpar;
Assert.AreEqual(0.20295512, cov[0, 0], 1.00); // From Python (these are scaled covariance values).
Assert.AreEqual(0.28479186, cov[1, 1], 0.01); // From Python (these are scaled covariance values).
Assert.AreEqual(0.01636735, cov[2, 2], 0.01); // From Python (these are scaled covariance values).
}
For completeness, here is the Python code:
Code:
from lmfit import minimize, Parameters
import numpy as np
# The Method that encapsulates the second order polynomial Model that will be fit to measured pressure data
def SecondOrderModel(params, x):
a0 = params['a0']
a1 = params['a1']
a2 = params['a2']
returnValue = a0 + a1 * x + a2 * pow(x, 2)
return(returnValue)
# This Method returns the difference between the measured and fitted values and is needed by the LM fitting routine
def residualSecondOrderModel(params, x, y, uncertainty):
theModel = SecondOrderModel(params, x)
returnValue = (y - theModel)/(uncertainty)
return(returnValue)
# --- Main Routine ---
# Initial Guesses (IGs).
IG_a0 = 10.0
IG_a1 = 0.0
IG_a2 = 0.0
x_ToFit = np.array([0.0, 1.0, 2.0, 3.0, 4.0 ])
#y_ToFit = np.array([3.9 + 0.0 + 0.0, 3.9 + 2.0 + (-0.0), 3.9 + 8.0 + 0.0, 3.9 + 18.0 + 0.0, 3.9 + 32.0 + -0.0]) # 3.9 + 0x + 2x^2 with no noise
y_ToFit = np.array([3.9 + 0.0 + 0.3, 3.9 + 2.0 + (-0.2), 3.9 + 8.0 + 0.4, 3.9 + 18.0 + 0.5, 3.9 + 32.0 + -0.4]) # 3.9 + 0x + 2x^2 with a bit of hand-made noise
# Set all uncertainties to 1.0 - Numerical Recipes, Third Edition, Section 15.4 (page 788) & initialize parameters
uncertainty = np.ones(x_ToFit.size)
params2ndOrder = Parameters()
params2ndOrder.add("a0", value = IG_a0)
params2ndOrder.add("a1", value = IG_a1)
params2ndOrder.add("a2", value = IG_a2)
out2ndOrder_lmfit_T = minimize(residualSecondOrderModel, params2ndOrder, args = (x_ToFit, y_ToFit, uncertainty), scale_covar=True)
print("--- SCALED COVARIANCE (scale_covar = True) ---")
print(out2ndOrder_lmfit_T.params["a0"])
print(out2ndOrder_lmfit_T.params["a1"])
print(out2ndOrder_lmfit_T.params["a2"])
print(out2ndOrder_lmfit_T.covar)
out2ndOrder_lmfit_F = minimize(residualSecondOrderModel, params2ndOrder, args = (x_ToFit, y_ToFit, uncertainty), scale_covar=False)
print("--- UNSCALED COVARIANCE (scale_covar = False) ---")
print(str(out2ndOrder_lmfit_F.params["a0"]) + " a0_T/a0_F = " + str(out2ndOrder_lmfit_T.covar[0][0] / out2ndOrder_lmfit_F.covar[0][0]))
print(str(out2ndOrder_lmfit_F.params["a1"]) + " a1_T/a1_F = " + str(out2ndOrder_lmfit_T.covar[1][1] / out2ndOrder_lmfit_F.covar[1][1]))
print(str(out2ndOrder_lmfit_F.params["a2"]) + " a2_T/a2_F = " + str(out2ndOrder_lmfit_T.covar[2][2] / out2ndOrder_lmfit_F.covar[2][2]))
print(out2ndOrder_lmfit_F.covar)

